Select * from student where studid = 103;
Select * from student where studid = 107;
Execution without index will return value for the second query at eights comparison.
Execution of second query with index will return the value at the third comparison. Look below:
- Compare 107 vs 103 : Move to right node
- Compare 107 vs 106 : Move to right node
- Compare 107 vs 107 : Matched, return the record
The primary key created for the
StudId column will create a clustered index for the Studid column. A table can have only one clustered index on it.
When creating the clustered index, SQL server 2005 reads the
Studid column and forms a Binary tree on it. This binary tree information is then stored separately in the disc. Expand the table Student and then expand theIndexes. You will see the following index created for you when the primary key is created:
With the use of the binary tree, now the search for the student based on the
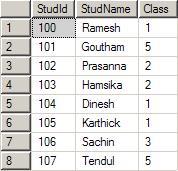
studid decreases the number of comparisons to a large amount. Let us assume that you had entered the following data in the table student:
The
index will form the below specified binary tree. Note that for a given parent, there are only one or twoChilds. The left side will always have a lesser value and the right side will always have a greater value when compared to parent. The tree can be constructed in the reverse way also. That is, left side higher and right side lower.
Now let us assume that we had written a query like below:
Execution without index will return value for the first query after third comparison.
Execution of first query with index will return value at first comparison.
If numbers of records are less, you cannot see a different one. Now apply this technique with a Yahoo email user accounts stored in a table called say
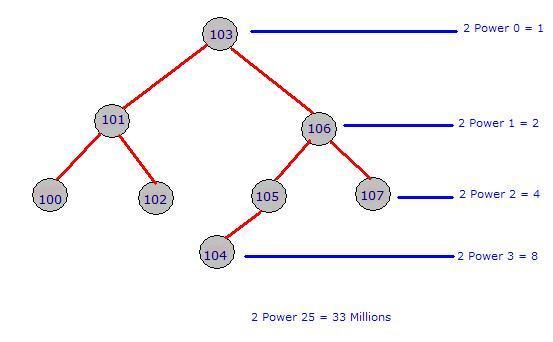
YahooLogin. Let us assume there are 33 million users around the world that have Yahoo email id and that is stored in the YahooLogin. When a user logs in by giving the user name and password, the comparison required is 1 to 25, with the binary tree that is clustered index.
Look at the above picture and guess yourself how fast you will reach into the level 25. Without Clustered index, the comparison required is 1 to 33 millions.
Got the usage of Clustered index? Let us move to Non-Clustered index.